SDBF:智能 DNS 爆破
0x00 摘要
域名的结构与提供对给定企业的管理、组织和运营的见解高度相关。对网络中的主机和服务进行安全性评估,以确定网络中的目标和服务。跟踪流行的僵尸网络使用的域名是另一个需要隐藏其底层DNS结构的主要应用程序。
目前的方法仅限于简单的暴力扫描或反向域名系统,但这些都是不可靠的。
暴力攻击依赖于一个庞大的已知单词列表,因此,不会针对未知名称工作,而反向DNS并不总是设置或正确配置。本文讨论了快速高效地生成DNS名称的问题,并描述了针对实际大规模DNS名称的实际经验。我们的方法基于自然语言建模的技术,利用马尔可夫链模型来构建第一个DNS扫描器(SDBF),它同时利用训练和高级语言建模方法。
0x01 介绍
DNS是指域名系统,代表一个层次化的命名系统,它将域名从人类可读的形式转换为连接到互联网上的计算机/服务的IP地址。这不仅使DNS成为上网必不可少的工具,而且填补了作为人机接口的空白。这也使得DNS对攻击者具有吸引力。例如,DNS探测是侦察阶段的一项重要任务,攻击者在该阶段收集信息。DNS显示有关潜在目标的有价值的信息,例如基础设施信息、MX或NS记录等。这些有价值的信息可以作为攻击的攻击点,例如,在适当配置的网络中不应启用恶意区域传输,因此需要进行探测。
本文提出了一种新的域名生成方法。智能DNS Brute Forcer(SDBF)工具依赖于一种称为n-gram模型的自然语言处理方法,该方法使用Markov链来合成新的DNS名称。这些新创建的DNS名称在网络上进行验证,并通过与其他工具进行比较来评估。
论文的结构安排如下:第二节介绍了SDBF模型,介绍了SDBF模型的主要特点和模块。此外,本节还介绍了如何通过引用具有马尔可夫链的n-gram模型生成新的DNS名称。第三节讨论了实验结果,并对其性能进行了评价。第四节介绍了这一领域的相关研究工作,第五节描述了可能的未来工作并提出了结论
0x02 结构
SDBF工具由两个不同的模块组成,处理器和生成器。处理器生成统计信息并从被动DNS输入中提取特征。它负责生成n元概率分布(见第II-B节)。生成模块用于组成使用n元概率的新DNS名称。然后通过执行DNS探测来验证新创建的DNS名称。图1显示了SDBF的体系结构。
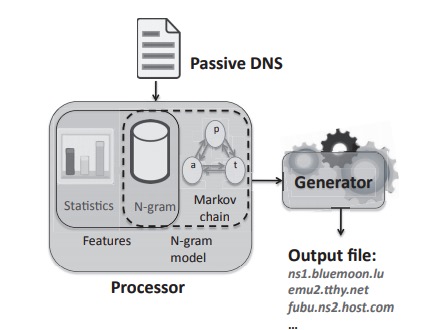
图1:智能DNS爆破(SDBF)的体系结构
1.特征和统计参数
为了使用SDBF生成新的DNS名称,已经确定了一些特性。这些特征主要是对不同语言属性的分布,例如字符分布。由本地网络运营商提供的被动DNS文件被用来提取这些特征。DNS文件有一组DNS名称N = {n1, …, nP }一组字符C={c1,…,cM},一组以给定字符开头的n个字,例如x,Gx={x1,…,xT}和一组域名级别L={l1,…,lS},其中#L设置为4。本文用#表示集合的基数。
我们定义,#wlenn:具有n个单词的DNS名称的数目#leni,j:具有j个字符的第i级(i∈L)的字数#firstchari,j:以字符j∈C#ngrami,j,k:在第i层上,字符j∈C后跟字符k∈C,i∈L的次数
下表重新组合处理器提取的不同特征,
- DNS名称中的字数
- 以字符表示的级别l的单词长度分布distleni可以定义为DNS名称中级别i的域单词的长度
- i级单词中出现最多的第一个字符firstchari的分布距离,
- 从被动DNS文件中提取n个gram的分布,称为n-gram。第II-B小节详细描述了n-gram模型。
- n-gram的分布可以定义为
除这些特征外,还进行了一些统计评估,以完成数据集和模型评估。这包括
- 一个文件中DNS条目的数量,nall
- 以字符为单位的平均DNS名称长度,包括数字和特殊字符(即-、/、2等)
- DNS名称的每个字符、数字或特殊字符的字符频率
2.N-gram模型
在自然语言处理中,n-gram1是从语料库(文本、句子等的集合)中提取的一个字符串的n个连续字符的序列,长度n=1、2、3、4,。。。。长度为1的n元称为一元,n=2称为二元。通过对DNS名称的首次手动调查,本文中的n-gram方法不仅考虑字母,还考虑特殊字符和数字,因为域名无法与简单的文本进行比较。为了举例说明n-gram,请考虑下面的test1.ex2ample.net
n = 1, t, e, s, t, 1, …
n = 2, te, es, st, t1, …
n = 3, tes, est, st1, …
在第一步中,使用被动DNS文件作为训练,通过应用第II-a节中的公式生成n-gram频率。使用包含Markov链的n-gram模型合成新的DNS名称。参考2,1的符号,假设X=X1,…,Xm作为一组随机变量,马尔可夫链可以定义为一组状态S={s1,s2,…,sr},其中一个过程从一个给定的状态开始,连续地从一个状态移动到另一个状态或保持在同一个状态,这个移动称为step。马尔可夫链尊重马尔可夫特性1,即未来状态只依赖于当前状态(历史)。
一个状态以一定的概率变为另一个状态或以一定的概率保持在同一个状态,这也称为转移概率。这些跃迁概率取自n-gram分布。如果pij状态的概率保持在相同的状态,则概率不变。此外,关于S的初始概率分布标志着Markov链的起始状态。图2中给出了一个马尔可夫链的状态图示例。给出了从一种状态到另一种状态的n元跃迁概率。这里,“u”后跟“n”的概率为0.4,而“u”后跟字母“i”的概率为0.6。一个“i”后面跟着另一个“i”的概率是0.2。
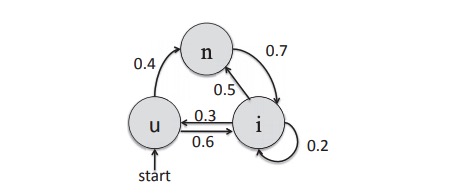
图2:n-gram 的马尔可夫链
3.生成器模块
图3中的生成器模块负责生成新的DNS名称。在第一步中,通过触发DNS名称中字数的随机数或使用自定义字数生成域字数,请参阅图3(1)。对于每个生成的单词,字符长度由用户设置或使用distwleli随机生成,即单词级别i的单词长度分布,参见(2)。对于每个域名,第一个字符是通过使用第一个字符分布随机选择的,见(3)。以n元模型生成的Markov概率转移矩阵和生成的单词长度作为输入,应用最可能的连续n个单词(基于概率分布)生成单词。用户还可以定义DNS名称的子部分,请参见(2’)。例如,在图3中,必须创建一个3个单词的DNS名称,并且用户已经将第二个级别设置为uni。第一级自动生成为snt。通过使用上述方法之一添加第三级,然后给出完整的域名snt.uni.lu公司. 因此,用户可以很容易地探测与正则表达式(如ns.*.lu)匹配的域名。
为了使DNS名称的创建更加灵活,所有发行版都考虑了一个因素。例如,即使学习数据库不包含任何以z开头的第一级单词,也可以生成这个单词,同时引入这个小概率因子。SDBF可以并行运行,从多个位置进行探测,而不必多次探测同一DNS名称。此外,语言特性可能会被丢弃,因为参与机器可以位于不同的国家,每个国家都有自己的本地特征数据库。此外,由于可靠性的原因,大型企业网络部署了多个权威服务器。通过从多个内部位置对该服务器执行并行和迭代查询,可以发现差异,这可能表示配置错误。

图3:生成器模块
0x03 实验结果
1.学习数据
已使用的学习数据集由本地操作员提供。此数据集描述了解析程序和权威服务器之间捕获的大约1小时的被动DNS监视活动。下表重组了学习数据集的主要特征,

表一:学习数据集的特征
2.验证
由于SDBF的目标是发现主机名,实验评估考虑 #D 已在探测域上发现的名称数。由于这些数字高度依赖于探测域,因此两个域之间的数量级可能会有很大的变化。因此,这应该表示为应该发现的实名总数的比率。实际上,获得这样的信息是不可能的
已在探测域上发现的名称数。由于这些数字高度依赖于探测域,因此两个域之间的数量级可能会有很大的变化。因此,这应该表示为应该发现的实名总数的比率。实际上,获取这些信息是不可能的。性能评估是基于与其他现有工具的比较:fire3和DNSenum4,这两个工具都包含在Backtrack5中,这是一个被安全专家广泛用于渗透测试的linux发行版。在5中,DNS探测是通过应用通用机器名字典来完成的。DNSenum包括一个266930个词条的大词典,而firefer只有1895个词条。SDBF不限制要生成的名称数量。因此,将该值设置为280000,以便具有与DNSenum相似的值,包括一个空白,以查看更多主机名的测试是否仍然有效。其他一些技术如Google,为了获取更多关于某个域中的活主机的信息而放弃。由于这些技术超出了纯DNS探测的范围,这种应用程序已经被丢弃。
SDBF验证假定每个工具发现的DNS名称的数目:#Dsdbf、#Ddnsenum和#Dfierce。
这也可以表示为任何工具可以发现的最大名称数的比率
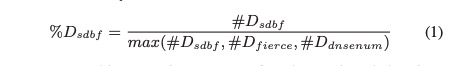
然而,这个实验是面向虚拟主机的,在虚拟主机中,同一个主机可能匹配不同的名称。这允许一台主机在同一个端口上承载多个服务。一个标准的例子是web服务器,其中的DNS名称区分了网站和想要访问的用户(更多细节见6)。一个简单的解决方案是只考虑不同的IP地址,但这似乎过于限制,因为检测不同的服务很重要,即使它们是在同一台机器上执行的。但是,用不同的主机名探测某些域总是会返回积极的结果,而且在许多情况下是公共web服务器。
但这些情况并不相关,因此IP地址也被考虑在内。否则,保留域名。
实验集中在A请求上,但是SDBF也可以被配置成可以使用其他类型的请求
3.主机名探测
第一组实验旨在识别给定域的所有宿主。例如,一个目标领域是大学领域,uni.lu 目标是检测与正则表达式匹配的名称。.uni.lu像www.uni.lu。
此外,SDBF还将探测其他子域并生成如下请求www.snt.uni.lu,因为后面的学习数据包括最多4个单词的域名(见III-A。
表II显示了一个探测域名的发现主机数量,检查了条目数D和速率%D。从表2中可以看出,它首先保存了一些来自卢森堡的本地域,其次是位于世界各地的域,称为world。SDBF是最有效的工具,因为它发现了最大数量的有效名称,永久性比率超过50%。假设75%的最佳结果,该比率至少为85%,尽管对于fire和DNSenum,这个值分别下降到69%和51%。
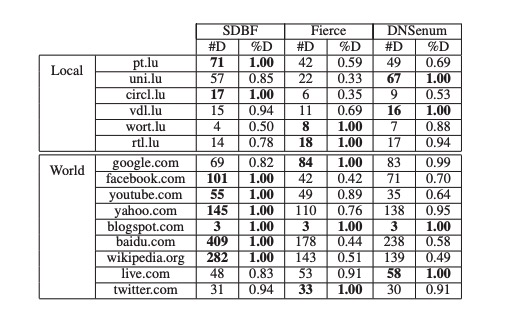
表二:发现有效名称的效率(粗体表示每个域的最佳工具)
与基于本地的域相比,SDBF似乎更适合在全球范围内进行探测,即使它是使用本地DNS捕获进行训练的。这可能是因为世界域名已经从Alexa网站的排名靠前的网站中提取出来7,这导致了对后台有许多主机的著名大型域名的调查,而卢森堡的本地域名规模较小,主机较少。像使用SDBF一样,生成各种DNS名称是高效的。
4.发现速度
SDBF可以生成无限多个新的DNS名称来进行探测,因此,与普通的基于字典的工具相比,SDBF有更大的机会发现更多的主机。被探测的进程的数量被定义为有效的进程名。可从该工具得出的单个速率值
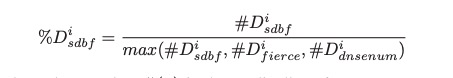
其中,符号#(x)是集合x的基数
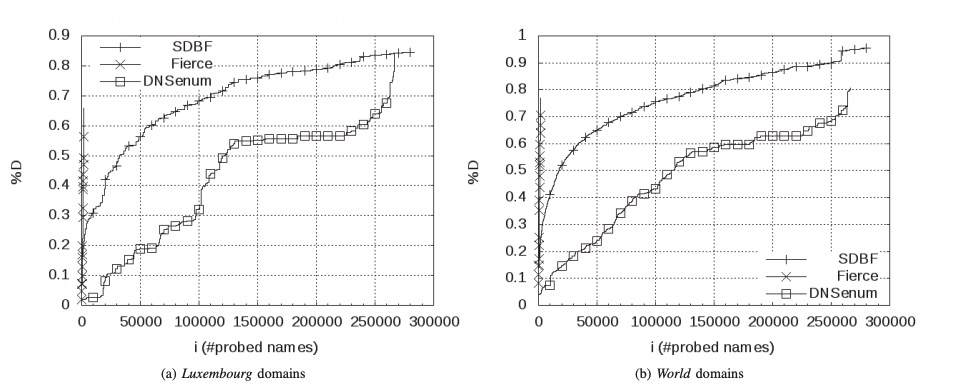
图4(a)和图4(b)绘制了该指标,其中计算了卢森堡和全球所有探测域的平均值。Fierce很快就能找到宿主,但由于它的字典很小(1895个主机名),它可能会漏掉不太常见的名字。其他工具的发现速度较低,但匹配的名称更多。比较DNSenum和SDBF,后者总是更快,除了在曲线末端DNSenum更好。事实上,字典是按字母顺序(通常是这样)使用的,DNSenum曲线中的斜率变化意味着有效名称存在于接近字母的位置。例如,上一次坡度变化主要是由于以下名称www、www2、web等。
5.工具互补性
在前面的实验中,评估是基于成功探测到的DNS名称的数量。然而,有时用一个精心设计的词典可以达到很好的效果。但是,这可能导致只探测常见名称,如web、ftp或邮件服务器。SDBF超出了这一限制,可以看作是一种补充工具。因此,下一个实验通过计算其他工具没有看到的成功探测名称的数量来评估互补性。根据之前定义的面额,定义了三组,
- Ssdbf :SDBF发现的名称
- Sdnsenum: DNSenum发现的名字
- Sfierce: Fierce发现的名字
图5是一个示例。工具的唯一性度量可以定义为成功探测的名称数与生成的名称总数之间的比率。该度量由图中的灰色阴影区域表示,并且对于每个工具t∈t={sdbf,dnsenum,f ierce}正式定义为:
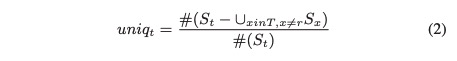
为了加强验证,通过计算以下指标来考虑SDBF与其他工具的互补性(见图5):
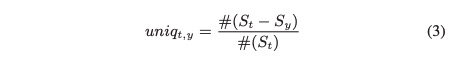
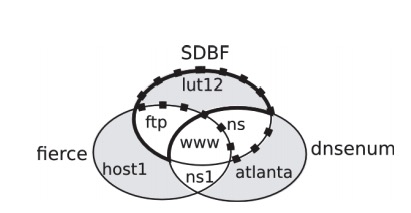
图5:工具的互补性-阴影区域表示工具的唯一性度量,虚线和粗线分别界定了SDBF与DNSenum和fire的互补性
为了集中精力评估SDBF,t总是固定为SDBF,如等式3所示。
图6全面总结了结果。
x轴表示按uniqt降序排序的域,但表示为索引,因为每个工具的顺序可能不同。因此,第一个索引可能不代表同一个域,但这里的目标不是通过计算发现的唯一性来比较每个域的工具。从总体上看,这两种工具具有相似的性能,但SDBF具有较高的平均比率(0.69)而稍有优势。因为索引已经排序
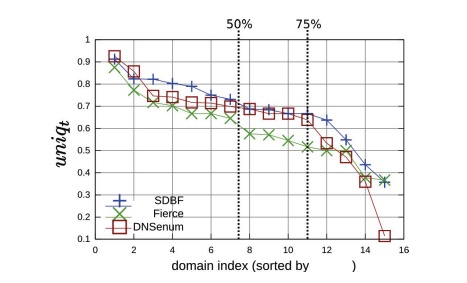
图6:发现的有效名称的唯一性-索引表示按uniqt排序的域
图6用一条垂直线显示了第50和第75个百分位。因此,在SDBF中75%的uniqsdbf值(0.67)高于fire(0.52)和DNSEnum(0.54)。这意味着SDBF能够探索各种DNS名称,而这些名称还没有被其他工具发现。简言之,所有测试工具都是非常互补的。
图7显示了SDBF针对每个工具(uniqsdbf,y)发现的值的唯一性。与DNSenum相比,SDBF发现的DNS名称似乎更为独特。然而,这种小偏差主要是由于词典非常小。此外,情况并非总是如此,尤其是rtl.lu公司以及脸谱网其中uniqsdbf,fierce相当于uniqsdbf,dnsenum。这样的例子证明,即使是SDBF也使用随机过程来生成域名,而学习阶段对于生成新的有效名称是相当有效的,就像那些已经被输入到专家词典中的域名一样
综上所述,SDBF能够发现更多的DNS名称,而其中大多数不是通过基于字典的方法发现的。这就证明了SDBF的成本是合理的,即使需要生成许多请求。例如,实验需要生成28万个名字,不像“fierce”被限制为1895个名字。
因此,必须在要发现的名称和要过滤的风险之间进行正确的权衡,因为从网络的角度来看,SDBF非常嘈杂。为了避免这个问题,可以像II-C中提到的那样,在多台机器上分布扫描,但是另一种选择是使用缓存服务器。通过利用迭代查询,SDBF可以直接探测非权威服务器的缓存,从而将自己隐藏在目标域之外。为了提高效率,这种方法必须查询高负载的服务器,比如Google的公共DNS8。
6.域名探测
基于字典的常用工具被设计用来探测一个域的所有主机名,就像之前的实验一样。
例如,它们可以生成与常规表达式类似*.uni.lu. SDBF能够匹配像ns..lu(在.lu域中查找名称服务器)这样的表达式,因为它单独处理每个单词,用户可以设置名称结构。下面是域的无效探测域名的一些示例 *.pt.lu公司都给了。
gbnsy.1bl.pt.lu
sa174fz7246fof35to.du.pt.lu
nes.pt.lu
有效域名的一些示例是,
www.pt.lu
roma.pt.lu
mmail.pt.lu
在另一个实验中,对卢森堡的FTP9和域名服务器进行了探索。这与以下表达式匹配:ns..lu和ftp..lu。即使这个实验没有包括所有可能存在的名称,最后还是发现了30个名称服务器和706个FTP服务器
0x04 相关工作
在DNS分析的研究领域,论文主要可以分为两大类:调查和实现解决方案的论文。与此研究领域相关的第一类论文是已进行的调查,如10、11。这些描述了可能的攻击方案,如可疑端口号、群发邮件、垃圾邮件、快速流量等,以及相应的对策。第二类论文应用了统计评估的方法或提出了重新设计域名系统的新方法12,但只有少数论文涉及域名知识[13],[14]。
例如,在文章[15]中,作者希望检测各种快速中毒攻击,这些攻击通过对事务组件的不同盲离路径猜测方法操纵解析缓存,这些方法用于DNS消息完整性。在这种攻击中,客户端被重定向到有害站点的新的不同IP地址。为了对抗这种攻击,在[15]中,它被称为具有白名单和不同类型分类器的统计评估,如k-最近邻或支持向量机来检测RR数据中的异常。在[16]中,作者描述了在本地网络上部署大学监控工具并监控网络活动。[16] 描述了不同可能的DNS异常,并作为评估工具绘制了不同的统计数据,例如,通过简单地研究DNS条目中的排版错误或快速流量域的IP地址的变化量。在[17]中,描述了一个大规模的被动DNS工具。
Exposure描述了一个大型的被动DNS分析工具,它依赖于15个不同特性的选择。特别是对各种异常行为的检测,而不是其中的一种。定义的特征是基于时间的长周期分析,或者计算条目之间的欧几里德距离以检测突变。例如,他们发现短寿命域只有两个突然的行为变化,而长寿域有多个行为变化。
在他们的实验中,他们使用了一个经过一周训练的分类器,然后他们只能测试他们的工具。
此外,通过在Google上手动检查域名的不同实验来估计假阳性率。本文主要分析了18个域名服务器的自动版本。
在分析中,他们使用相似性指标Jaccard索引来比较聚集的(/24)IP地址集。为了分析网络范围内的模式,他们只需计算Jaccard索引的平均值,就可以将域重新组合成不同的类别,例如网络钓鱼、垃圾邮件等。
可以看出,很多研究主要集中在对DNS攻击的异常评估上。本文主要研究网络上域的可见性问题。因此,另一个焦点是看域名本身。最近观察到的一个趋势是在法医学和安全研究中使用自然语言处理技术。例如[13],其中域名是自动的。它们引用基于音节的算法来生成密码或用户名。与本文的主要区别在于它们主要是生成完整的单词,在我们的方法中使用了n-gram方法,使得字符可以通过概率分布生成单词。
在[19]中,使用[13]中的技术生成域名。借助统计方法,如KulbackLeibler散度或编辑距离度量,可以检测出由著名僵尸网络产生的域名。文献[14]提出了在侦察阶段提取DNS元数据的不同方法。因此,一个推理算法,如字典攻击或暴力强迫被用来产生名称和发送到DNS解析程序。
关于安全方面的另一个有趣的工作是[20]的论文,其中提到了概率上下文无关语法来生成破解密码的规则。
0x05 结论
本文介绍了一种新的DNS名称智能生成方法,即n-gram模型。SDBF的优点是它不局限于词典知识,因为这类专家工具很常见。
实验表明,SDBF比基于字典的工具能够发现更多的名字。这可以解释为,n-gram模型不需要生成现有的单词,也可以生成简单的字符序列,包括数字和DNS名称的特殊字符