简单理解污点分析技术
0X00 前言
同符号执行一样,污点分析也是我们分析代码漏洞,检测攻击方式的重要手段,在漏洞自动化扫描或者检测工具中有着十分广泛的应用,本文主要是对污点分析进行一些简单的介绍,文中内容来源于网络,在最后我会附上参考的文章以及论文的链接。
0X01 污点分析基本原理
1.污点分析定义
污点分析可以抽象成一个三元组<sources,sinks,sanitizers>的形式,其中,source 即污点源,代表直接引入不受信任的数据或者机密数据到系统中;sink即污点汇聚点,代表直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性);sanitizer即无害处理,代表通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害.污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污点汇聚点.如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危险数据操作等安全问题.
污点分析的处理过程可以分成 3 个阶段(如图 2 所示):
(1) 识别污点源和汇聚点;
(2) 污点传播分析;
(3) 无害处理.
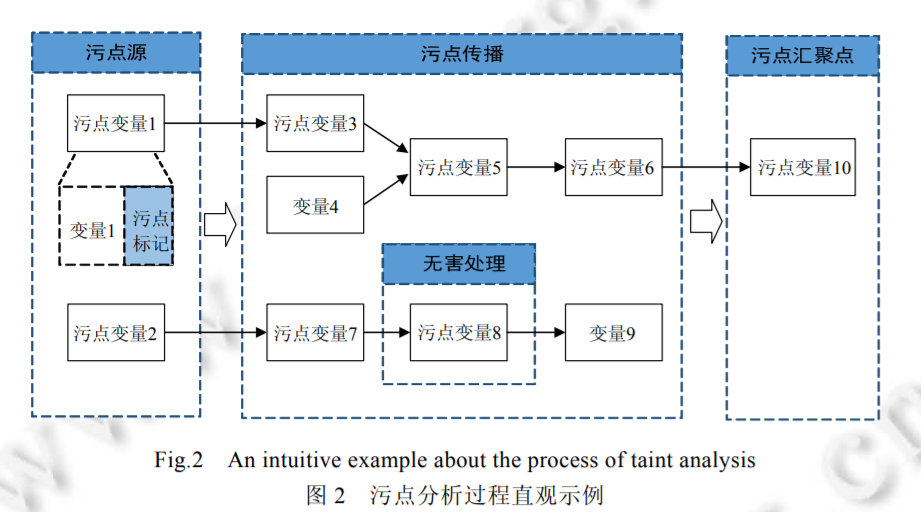
2.识别污点源和汇聚点
识别污点源和污点汇聚点是污点分析的前提.目前,在不同的应用程序中识别污点源和汇聚点的方法各不
相同.缺乏通用方法的原因一方面来自系统模型、编程语言之间的差异.另一方面,污点分析关注的安全漏洞类
型不同,也会导致对污点源和污点汇聚点的收集方法迥异.表 1 所示为在 Web 应用程序漏洞检测中的污点源示
例[29],它们是 Web 框架中关键对象的属性.

现有的识别污点源和汇聚点的方法可以大致分成 3 类:
(1)使用启发式的策略进行标记,例如把来自程序外部输入的数据统称为“污点”数据,保守地认为这些数据有可能包含恶意的攻击数据(如 PHP Aspis);
(2)根据具体应用程序调用的 API 或者重要的数据类型,手工标记源和汇聚点(如 DroidSafe);
(3)使用统计或机器学习技术自动地识别和标记污点源及汇聚点.
3.污点传播分析
污点传播分析就是分析污点标记数据在程序中的传播途径.按照分析过程中关注的程序依赖关系的不同, 可以将污点传播分析分为显式流分析和隐式流分析.
(1)显示流分析
污点传播分析中的显式流分析就是分析污点标记如何随程序中变量之间的数据依赖关系传播.

以图 3 所 示的程序为例,变量 a 和 b 被预定义的污点源函数 source 标记为污点源.假设 a 和 b 被赋予的污点标记分别为taint_a 和 taint_b.由于第 5 行的变量 x 直接数据依赖于变量 a,第 6 行的变量 y 直接数据依赖于变量 b,显式流分析会分别将污点标记 taint_a 和 taint_b 传播给第 5 行的变量 x 和第 6 行的变量 y.又由于 x 和 y 分别可以到达第 7 行和第 8 行的污点汇聚点(用预定义的污点汇聚点函数 sink 标识),图 3 所示的代码存在信息泄漏的问题.我们将在后面具体介绍目前污点传播分析中显式流分析面临的主要挑战和解决方法.
(2)隐式流分析
污点传播分析中的隐式流分析是分析污点标记如何随程序中变量之间的控制依赖关系传播,也就是分析污点标记如何从条件指令传播到其所控制的语句.

在图 4 所示的程序中,变量 X 是被污点标记的字符串类型变量,变量 Y 和变量 X 之间并没有直接或间接的数据依赖关系(显式流关系),但 X 上的污点标记可以经过控制依赖隐式地传播到 Y.
具体来说,由第 4 行的循环条件控制的外层循环顺序地取出 X 中的每一个字符,转化成整型后赋给变量 x,再由第 7 行的循环条件控制的内层循环以累加的方式将 x 的值赋给 y,最后由外层循环将 y 逐一传给 Y.最终,第 12 行的 Y 值和 X 值相同,程序存在信息泄漏问题.但是,如果不进行隐式流污点传播分析,第 12 行 的变量 Y 将不会被赋予污点标记,程序的信息泄漏问题被掩盖.
隐式流污点传播一直以来都是一个重要的问题,和显式流一样,如果不被正确处理,会使污点分析的结果不精确.由于对隐式流污点传播处理不当导致本应被标记的变量没有被标记的问题称为欠污染(under-taint)问题.相反地,由于污点标记的数量过多而导致污点变量大量扩散的问题称为过污染(over-taint)问题.目前,针对隐式流问题的研究重点是尽量减少欠污染和过污染的情况.我们将在后面具体介绍现有技术是如何解决上述问题的.
4.无害处理
污点数据在传播的过程中可能会经过无害处理模块,无害处理模块是指污点数据经过该模块的处理后,数据本身不再携带敏感信息或者针对该数据的操作不会再对系统产生危害.换言之,带污点标记的数据在经过无害处理模块后,污点标记可以被移除.正确地使用无害处理可以降低系统中污点标记的数量,提高污点分析的效率,并且避免由于污点扩散导致的分析结果不精确的问题.
在应用过程中,为了防止敏感数据被泄露(保护保密性),通常会对敏感数据进行加密处理.此时**,加密库函数应该被识别成无害处理模块**.这一方面是由于库函数中使用了大量的加密算法,导致攻击者很难有效地计算出密码的可能范围;另一方面是加密后的数据不再具有威胁性,继续传播污点标记没有意义.
此外,为了防止外界数据因为携带危险操作而对系统关键区域产生危害(保护完整性),通常会对输入的数据进行验证.此时,输入验证(input validation)模块应当被识别成无害处理模块.
例如,为了防止代码注入漏洞,PHP 提供的 htmlentities 函数可以将特殊含义的 HTML 字符串转化成HTML实体(例如,将’<’转化成’<’).输入字符串经过上述转化后不会再携带可能产生危害的代码,可以安全地 发送给用户使用.除了语言自带的输入验证函数外,一些系统还提供了额外的输入验证工具,比如ScriptGard,CSAS,XSS Auditor,Bek.这些工具也应被识别成无害处理模块.
综上,目前对污点源、污点汇聚点以及无害处理模块的识别通常根据系统或漏洞类型使用定制的方法.由于这些方法都比较直接,本文将不再进行更深入的探讨.下一节将重点介绍污点传播中的关键技术.
0X02 污点传播分析的关键技术
污点传播分析是当前污点分析领域的研究重点.与程序分析技术相结合,可以获得更加高效、精确的污点分析结果.根据分析过程中是否需要运行程序,可以将污点传播分析分为静态污点分析和动态污点分析.本节主要介绍如何使用动/静态程序分析技术来解决污点传播中的显式流分析和隐式流分析问题.
1.污点传播中的显式流分析
(1)静态分析技术
静态污点传播分析(简称静态污点分析)是指在不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从污点源传播到污点汇聚点.
静态污点分析的对象一般是程序的源码或中间表示.可以将对污点传播中显式流的静态分析问题转化为对程序中静态数据依赖的分析:
(1)首先,根据程序中的函数调用关系构建调用图(call graph,简称CG);
(2)然后,在函数内或者函数间根据不同的程序特性进行具体的数据流传播分析.常见的显式流污点传播方式包括直接赋值传播、通过函数(过程)调用传播以及通过别名(指针)传播.
以图 5 所示的 Java 程序为例:

第 3 行的变量 b 为初始的污点标记变量,程序第 4 行将一个包含变量 b 的算术表达式的计算结果直接赋给变量 c.由于变量 c 和变量 b 之间具有直接的赋值关系,污点标记可直接从赋值语句右部的变量传播到左部,也就是上述 3种显式流污点传播方式中的直接赋值传播.
接下来,变量 c 被作为实参传递给程序第 5 行的函数 foo,c 上的污点标记也通过函数调用传播到 foo 的形参 z,z 的污点标记又通过直接赋值传播到程序第 8 行的 x.f.由于 foo 的另外两个参数对象 x 和 y 都是对对象 a 的引用,二者之间存在别名,因此,x.f的污点标记可以通过别名传播到第 9 行的污点汇聚点,程序存在泄漏问题.
目前,利用数据流分析解决显式污点传播分析中的直接赋值传播和函数调用传播已经相当成熟,研究的重点是如何为别名传播的分析提供更精确、高效的解决方案.由于精确度越高(上下文敏感、流敏感、域敏感、对象敏感等)的程序静态分析技术往往伴随着越大的时空开销,追求全敏感且高效的别名分析难度较大.又由于静态污点传播分析关注的是从污点源到污点汇聚点之间的数据流关系,分析对象并非完整的程序,而是确定的入口和出口之间的程序片段.这就意味着可以尝试采用按需(on-demand)定制的别名分析方法来解决显式流态污点分析中的别名传播问题.有些使用按需的上下文敏感的别名分析的污点分析方法来检测 Java 应用程序漏洞.TAJ工具使用了混合切片结合对象敏感的别名分析来进行 Java Web 应用上的污点分析.Andromeda工具使用了按需的对象敏感别名分析技术解决对象的访问路径(access path)问题,FlowDroid工具提出一种按需的别名分析,从而提供上下文敏感、流敏感、域敏感、对象敏感的污点分析,用以解决 Android的隐私泄露问题.
(2)动态分析技术
动态污点传播分析(简称动态污点分析)是指在程序运行过程中,通过实时监控程序的污点数据在系统程序中的传播来检测数据能否从污点源传播到污点汇聚点.动态污点传播分析首先需要为污点数据扩展一个污点标记(tainted tag)的标签并将其存储在存储单元(内存、寄存器、缓存等)中,然后根据指令类型和指令操作数设计相应的传播逻辑传播污点标记.
动态污点传播分析按照实现层次被分为基于硬件、基于软件以及混合型的污点传播分析这3类.
1.硬件
基于硬件的污点传播分析需要定制的硬件支持,一般需要在原有体系结构上为寄存器或者内存扩展一个标记位,用来存储污点标记,代表的系统有 Minos,Raksha等.
2.基于软件
基于软件的污点传播分析通过修改程序的二进制代码来进行污点标记位的存储与传播,代表的系统有 TaintEraser[64],TaintDroid[19]等.
基于软件的污点传播的优点在于不必更改处理器等底层的硬件,并且可以支持更高的语义逻辑的安全策略(利用其更贴近源程序层次的特点),但缺点是使用插桩(instrumentation 在保证被测程序原有逻辑完整性的基础上在程序中插入一些探针)或代码重写(code rewriting)修改程序往往会给分析系统带来巨大的开销.相反地,基于硬件的污点传播分析虽然可以利用定制硬件降低开销,但通常不能支持更高的语义逻辑的安全策略,并且需要对处理器结构进行重新设计.
3.混合型
混合型的污点分析是对上述两类方法的折中,即,通过尽可能少的硬件结构改动以保证更高的语义逻辑的安全策略,代表的系统有 Flexitaint,PIFT等.
目前,针对动态污点传播分析的研究工作关注的首要问题是如何设计有效的污点传播逻辑,以确保精确的污点传播分析.
TaintCheck利用插桩工具 Valgrind对其中间表示 Ucode 插桩并提供移动指令、算术指令以及除移动和算术外其他指令的 3 类传播逻辑实现对 x86 程序的动态污点分析.Privacy Scope,Dytan和Libdft以插桩工具 Pin为基础,实现针对 x86 程序的动态污点分析,并解决了一系列 x86 指令污点传播逻辑的问题.TaintDroid提供了一套基于 Android Dalvik 虚拟机的 DEX 格式的污点传播分析方法.由于 DEX的指令包含多数常用的指令和具有面向对象特性的指令,普适性高,这里以TaintDroid中污点传播方法为示例,介绍动态污点传播的逻辑.
DEX 支持的变量类型有 5 种:本地变量、方法参数、类静态域、类实例域和数组.TaintDroid 用υX 代表本地变量和方法参数,fX 代表类的静态域,υY(fX)代表实例域,其中,υY是具体实例的变量引用.υX[⋅]代表数组,其中,υX表示数组的对象引用.
同时,TaintDroid 使用虚拟污点映射函数τ(⋅)来辅助污点传播,对于变量υ,τ(υ)返回变量的污点标记 t.τ(υ)可以被赋值给其他的变量.符号←代表将位于符号右部的变量的污点标记传播给左部的变量.具体的污点传播逻辑规则见表 2.
- 对常数、移动(赋值)、一元算术逻辑指令的传播逻辑是直接将指令的右值的污点标记传递给指令的
左值; - 对于多元算术逻辑指令,需要将指令的右值的污点标记进行合并之后传播给指令的左值;
- 对于返回指令和异常处理指令,分别将变量标记传递给与返回、异常处理相关的变量;
- 对于数组指令,除了对数组变量的标记进行传播外,还需要将数组索引变量的标记合并传播.例如,对于
数组赋值 b=Z[a],索引变量 a 的污点标记也需要传播给 b 变量; - 对于域操作相关指令,同样需要将对象的域变量污点标记以及域所属对象变量的标记进行合并传播.
动态污点传播分析的另一个研究重点是如何降低分析代价.如前所述,传统的基于硬件的动态污点传播分析技术需要定制硬件的支持,而基于软件的技术由于程序插桩或代码重写会带来额外的性能开销.为控制分析代价,一类研究工作采用的思路是有选择地对系统中的指令进行污点传播分析.例如,LIFT提出的快速路径(fast-path)优化技术通过提前判断一个模块的输入和输出是否是具有威胁的(如果没有威胁,则无需进行污点传播)以降低需要重写的代码的数量;合并检查(merged check)优化技术将多个基本块合并成 1个进行检查,以降低检查次数;
快速切换(fast switch)优化则利用活性分析消除一些之后不活跃的条件寄存器的 save 和 restore 操作,以减少需要分析的指令数量.PIFT系统提出了基于预测的污点跟踪(传播)方式,他们设计统计实验观察到CPU 指令流中 load 和 store 指令存在一些特殊性质(load 指令与其子序列中 store 指令距离接近、load 指令之后的 store 指令个数不多、连续的 load 指令之间的距离是均匀的).基于此,提出了基于预测的只跟踪 load 和 store指令的策略,即:**如果load指令的操作数是污点数据,那么将其一定距离内的store指令的目的地址标记成污点数据.**该方法减少了跟踪其他复杂CPU指令的开销.
**另外一类降低分析代价的思路是,使用低开销的机制代替高开销机制.**例如,SHIFT将动态污点分析转化成延迟例外(deferred exceptions)处理的问题.延迟例外是指在例外发生后,将例外标记在相关的指令中,之后再通过检测指令检测出被标记指令中的例外并处理例外,这种机制与污点标记传播的机制类似.SHIFT将污点传播分析实现在支持投机执行(speculative execution)的处理器中,既不需要改变计算机处理器本身,又可以充分利用该处理器高速处理延迟例外的优势,从而达到降低动态污点分析开销的效果.又比如,LIFT 的快速切换(fast switch)优化使用低开销的 lahf/sahf 指令代替高开销的 pushq/popq 指令,以提高插桩代码与原始二进制文件之间的切换效率.

2.污点传播中的隐式流分析
污点传播分析中的隐式流分析就是分析污点数据如何通过控制依赖进行传播,如果忽略了对隐式流污点传播的分析,则会导致欠污染的情况;如果对隐式流分析不当,那么除了欠污染之外,还可能出现过污染的情况.与显式流分析类似,隐式流分析技术同样也可以分为静态分析和动态分析两类.
(1)静态分析技术
**静态隐式流分析面临的核心问题是精度与效率不可兼得的问题.精确的隐式流污点传播分析需要分析每一个分支控制条件是否需要传播污点标记.路径敏感的数据流分析往往会产生路径爆炸问题,导致开销难以接受.为了降低开销,一种简单的静态传播(标记)分支语句的污点标记方法是将控制依赖于它的语句全部进行污点标记,**但该方法会导致一些并不携带隐私数据的变量被标记,导致过污染情况的发生.过污染会引起污点的大量扩散,最终导致用户得到的报告中信息过多,难以使用.
(2)动态分析技术
动态隐式流分析关注的首要问题是如何确定污点控制条件下需要标记的语句的范围.由于动态执行轨迹并不能反映出被执行的指令之间的控制依赖关系,目前的研究多采用离线的静态分析辅助判断动态污点传播中的隐式流标记范围.Clause等人提出,利用离线静态分析得到的控制流图节点间的后支配(post-dominate)关系来解决动态污点传播中的隐式流标记问题.
例如,如图 6(a)所示,程序第 3 行的分支语句被标记为污点源,当document.cookie 的值为 abc 时,会发生污点数据泄露.根据基于后支配关系的标记算法,会对该示例第 4 行语句的指令目的地,即 x 的值进行污点标记.

动态分析面临的第 2 个问题是由于部分泄漏(partially leaked)导致的漏报.部分泄漏是指污点信息通过动态未执行部分进行传播并泄漏.Vogt等人发现,只动态地标记分支条件下的语句会发生这种情况.
**仍以图 6(a)中的程序为例:**当第 3 行的控制条件被执行时,对应的 x 会被标记.此时,x 的值为 true,而 y 值没有变化,仍然为 false.在后续执行过程中,由于第 9行的污点汇聚点不可达,而第 12 行的汇聚点可达,动态分析没有检测到污点数据泄漏.但攻击者由第 11 行 y 等于 false 的条件能够反推出程序执行了第 3 行的分支条件,程序实际上存在信息泄漏的问题.这个信息泄露是由第 6 行未被执行到的 y 的赋值语句所触发的.因此,y 应该被动态污点传播分析所标记.为了解决部分泄漏问题,Vogt等人在传统的动态污点分析基础上增加了离线的静态分析,以跟踪动态执行过程中的控制依赖关系,对污点分支控制范围内的所有赋值语句中的变量都进行标记.具体到图 6(a)所示的例子,就是第 4 行和第 6 行中的变量均会被污点标记.但是,Vogt 等人的方法仍然会产生过污染的情况.
**动态分析需要解决的第 3 个问题是如何选择合适的污点标记分支进行污点传播.**鉴于单纯地将所有包含污点标记的分支进行传播会导致过污染的情况,可以根据信息泄漏范围的不同,定量地设计污点标记分支的选择策略.
以图 6(b)所示的程序为例,第 2 行的变量 a 为初始的污点标记变量.第 5 行、第 7 行、第 9 行均为以 a作为源操作数的污点标记的分支.如果传播策略为只要分支指令中包含污点标记就对其进行传播,那么第 5 行、第 7 行、第 9 行将分别被传播给第 6 行、第 8 行、第 10 行,并最终传播到第 12 行的污点汇聚点.如果对这段程序进行深入分析会发现,3个分支条件所提供的信息值(所能泄露的信息范围)并不相同,分别是 a 等于 10、a大于 10 且小于或等于 13(将 w 值代入计算)以及 a 小于 10.对于 a 等于 10 的情况,攻击者可以根据第 12 行泄漏的 x 的值直接还原出污点源处 a 的值(这类分支也被称为能够保存完整信息的分支);对于 a 大于 10 且小于或等于 13 的情况,攻击者也只需要尝试 3 次就可以还原信息;而对于 a 小于 10 的情况,攻击者所获得的不确定性较大,成功还原信息的几率显著低于前两种,对该分支进行污点传播的实际意义不大.
Bao等人只将严格控制依赖(strict control dependence)识别成需要污点传播的分支,其中,**严格控制依赖即分支条件表达式的两端具有常 数差异的分支.**但是,Bao 的方法只适用于能够在编译阶段计算出常数差异的分支.
Kang 等人提出的 DTA++ 工具使用基于离线执行踪迹(trace)的符号执行的方法来寻找进行污点传播的分支,但该方法只关注信息被完整保存的分支,即图 6(b)中第 5 行的 a==10 会被选择污点传播,但是信息仍然能够通过另一个范围(第 7 行的分支)而泄露.
Cox 等人提出的 SpanDex 的主要思想是:动态地获得控制分支中污点数据的范围,根据数据的更改以及数据间的依赖关系构建一个基于操作的有向无环图(OP-DAG),再结合一个在线的约束求解器(CSP solver)确定隐式流中传播的隐私数据值的范围,通过预先设定的阈值,选择是否对数据进行污点传播.该方法对图 6(b)所示例子中的第 5 行、第 7行的分支进行污点传播.但是目前,该方法只能求解密码字符的范围,暂不支持对复杂操作(位、除法、数组等操作)的求解.
0X03 污点分析在实际应用中的关键技术
污点分析被广泛地应用在系统隐私数据泄露、安全漏洞等问题的检测中.在实际应用过程中,由于系统框架、语言特性等方面的差异,通用的污点分析技术往往难以适用.比如:系统框架的高度模块化以及各模块之间复杂的调用关系导致污点源到汇聚点的传播路径变得复杂、庞大,采用通用的污点分析技术可能面临开销难以接受的问题;通用的污点分析技术对新的语言特性支持有限等.为此,需要针对不同的应用场景,对通用的污点分析技术进行扩展或定制.
本节以 Web 应用安全漏洞检测为切入点,总结污点分析技术在上述领域的应用实践过程中所面临的问题和关键解决技术.
目前,**Web 应用程序中存在大量的安全漏洞,如跨站脚本攻击、SQL 注入等.污点分析可以有效地检测这些安全漏洞.**基于 HTTP 协议的 Web 应用框架在总体上分成两大部分:服务器端应用程序和客户端应用程序.用户浏览 Web 网页时,浏览器通过 HTTP 协议与 Web 服务器交换信息.浏览器端上的应用程序被称为客户端应用程序.客户端应用程序使用 HTML 结合脚本语言(比如 JavaScript)处理和交换数据,再将数据显示在网页上.Web服务器端应用程序接收客户端脚本语言的请求(request),根据请求执行对应的逻辑计算或者数据库查询操作,然后返回一个响应(response)给客户端.如此往复地进行信息交换,完成网页浏览.
Web 应用程序中的安全漏洞可能发生在客户端的脚本程序中,也可能发生在服务器端的应用程序中,还可能是由服务器端和客户端程序合作触发的.无论是客户端的应用程序还是服务器端的应用程序,一旦安全漏洞被攻击者利用,都可能会给用户带来财产损失.目前的 Web 框架有数百种之多,本节选取一个服务器端 Web应用框架(Java EE)和一个客户端 Web 框架(JavaScript)为代表进行论述.
1.Java Web 框架上的污点分析技术
Java EE(Java platform,enterprise edition)框架是一种典型的服务器端 Web 应用程序框架,目前被广泛应用于企业级 Web 的构建.Servlets 和 Java Server Pages(JSP)是 Java EE 中两个最重要的部分.Servlet 类主要提供逻辑处理功能:通过处理接口与配置文件交互来处理客户端请求;JSP 通过在传统的 HTML 页面中插入 Java 程序段和 JSP 标记的方式提供页面显示.
在 Java EE 的基础上又扩展了很多其他框架,这些框架可以提供更高级别的 Web 开发抽象,比如基于 MVC
模型的 Struts 框架.Struts使用控制器(controller)处理主要业务逻辑,使用视图(view)渲染响应页面,使用模型(model)来存储数据模型.如图 10 所示是 Struts 处理 HTTP 请求的流程:当控制器 ActionServlet 收到一个 HTTP请求时,它会解析得到其 URL 并根据配置文件决定处理该请求的 Action 子类.同时,添加一个 ActionForm 对象用以存储请求的数据.Struts 会自动完成对 ActionForm 对象的填充并启动 Action 子类的对象,再通过 execute 方法读入 ActionForm 对象,以进一步处理相关业务逻辑.处理后的 Action 子类会返回一个 ActionForward 类,Struts会根据配置文件得出下一个跳转页面并转发给 JSP,由 JSP 将其渲染后发送到客户端进行显示.

如图 10 中虚线箭头所示为 Java EE 上的污点传播的分析过程:一般而言,Java EE 框架的污点来源于客户端的浏览器输入,但是 Java EE 框架不能直接分析浏览器中的客户端代码.考虑到浏览器中的内容直接来源于 JSP,污点分析首先需要获得 JSP 上相关的污点源信息;其次,Web页面间的跳转关系决定了污点的传播逻辑,其中,ActionServlet 通过 Java 的反射机制与配置文件交互决定由哪个 Action 类处理对应的页面跳转;最后,污点的汇聚点存在于具体的 Action 类的重要数据区域.上述分析过程表明:针对 Java EE 框架的污点传播分析仅仅实现在 Java 层是不够的,需要考虑到 Java 代码、配置文件、JSP 代码三者之间的交互处理问题.
为了将这三者的代码集中分析,Møller 等人将它们对应到 Java 代码中,提出了基于跟踪 Web程序状态的污点分析方法.
该方法包括 3 个步骤:识别客户端状态、识别共享程序状态和污点传播分析,
其中,识别客户端状态就是识别 JSP中能够直接引用服务器端的内部对象(比如数据库记录)的参数.具体方法是,首先分析配置文件中页面跳转关系信息,形成一张能够反映页面之间访问关系的图.图中的节点代表页面,边代表页面之间可能的跳转关系以及跳转过程中触发的 Action 和 From.对于一个 JSP 页面 p,识别引用参数的方法是将图中指向页面p 的边上的Action 类的参数和页面 p 中的文档参数(一般是隐藏字段、选择框、链接等)进行匹配,将能够被匹配的参数识别为客户端状态,也就是污点源.识别共享应用程序状态就是识别 Java 代码中重要的数据区域接口,也就是污点汇聚点.
共享应用程序状态包括两个部分:
(a) 内部应用程序状态,包括 HTTPServlet 对象、ServletContext 对象以及所有的静态域;
(b) 外部应用程序状态,即,存储在文件和数据库中的状态代码.污点传播
分析以识别出的客户端状态为污点源,以共享应用程序状态为污点汇聚点,判断客户端程序状态值是否会被写
入到内部程序状态对象或者能否调用外部程序状态.
Sridharan 等人提出的 F4F 使用了一种语言规范格式来解决不同语言代码间的交互问题.主要思想是:使用 Web 应用框架语言(Web application framework language,简称 WAFL)统一整个 Java EE 框架上的不同过程的代码,最后在 WAFL 的基础上进行污点分析.如图 11 所示是 WAFL 的文法规范,包括 3个部分:全局变量(global)、合成方法(synthetic methods)和调用替换(call replacement).

全局变量用来表示那些在不同模块之间传递的变量;合成方法对框架中不同模块的代码以及配置文件进行合成,将不同的代码放在一个方法中进行分析;调用替换表示一个调用点需要替换成一个具体的代码进行分析.F4F 还提供了一种有效的文法生成方法,生成的文法将作为污点分析的输入代码.
2.解决 JavaScript 上的污点分析
Web 脚本直接运行在客户端浏览器中,具有简单易学、开发速度快、可移植性强、便于集成成熟技术等优势.目前最流行的 Web 脚本语言是 JavaScript,它是一个灵活的动态脚本语言,提供面向对象特性、DOM 模型调用、与网络库动态交互信息等特性,可以提供更高的用户体验.例如:在使用 Gmail时,需要对用户名和密码进行验证,这个验证过程是静态 HTML 无法完成的,但可以利用 JavaScript 实现.
脚本语言同样面临严重的安全性问题.在使用 JavaScript 的过程中,重要数据(如定位信息、RSS 等)可能会通过第三方应用脚本进行处理.恶意的第三方应用可能导致恶意的软件行为,比如窃取用户的隐私数据、破坏用户的重要数据或者将页面重定位到具有恶意行为的页面等.污点分析技术可以被用于检测上述问题,但是由于 JavaScript 语言中包含的大量有别于传统的 C/C++/Java语言的新特性,需要对传统污点分析技术进行扩展.
JavaScript 上的污点分析首先需要解决 JavaScript 的特殊语法特性带来的问题,**目前的方法多使用代码重写的方式解决该问题.**有人提出了解决 JavaScript中函数、域、原型(prototypes)等特性带来的污点传播问题;ACTARUS在抽象语法树级别进行代码重写,主要解决由于原型系统、对象创建(object creations)、反射属性访问(reflective property accesses)、词法作用域(lexical scoping)等语言特性导致的难以建立完整的调用图的问题.
JavaScript 语言大量地使用动态特性来提高用户的体验,例如在运行时动态地加载第三方库、使用 eval 方法动态地产生执行代码等.**由于动态特性代码只有在运行时才能获得具体信息,传统的静态污点分析无法精确地分析出其中可能存在的安全问题.针对 JavaScript 语言的动态特性问题,Chugh 等人提出了分阶段的污点分析方法.分阶段污点分析的主要思想是尽可能地在当前已知的代码上进行静态污点分析并提取定制的检查规则,然后在动态加载过程中进行规则检查.**静态污点分析阶段使用一种基于约束求解的方法分析两个集合:必须不能写入集合(must not write set)和必须不能读取集合(must not read set).制定的检查规则是动态代码中的变量不能流入或流出到上述集合中.在动态阶段实施快速的规则检查,如果代码满足了规则检查,那么整个系统就被认为是安全的.Wei 等人提出了利用混合的污点分析技术来解决 JavaScript 漏洞检测中的动态语言特性问题.混合分析的主要思想是利用动态分析生成执行踪迹,在执行踪迹的基础上利用静态方法进行污点分析.在动态分析阶段中,利用已有的测试集合动态执行并收集执行踪迹.每个网页的执行踪迹包括执行过的函数调用、创建对象的类型和静态不可见的动态加载执行代码,选择程序行为覆盖度较高的执行踪迹页面的子集.在静态污点分析阶段,通过分析执行踪迹子集建立调用图,并在调用图上实施静态的污点分析.
基于 DOM 的 XSS 安全问题使得 JavaScript 的污点分析还需要考虑 JavaScript 与文档对象模型(DOM)的交互问题.Vogt 等人提出了一种简单的解决方案,它的实现思想是:如果一个 DOM 节点被污点标记,则需要为当前节点存储一个污点数据;如果当前节点在此之后被访问,那么它的返回值也会被污点标记.Lekies 等人提出了一种更为系统的解决方案,他们尝试通过修改浏览器源码来支持对基于 DOM 的 XSS 安全问题的污点分析,也称为动态的字符串级别的污点分析方法.该方法将 14 个污点源(例如 location.href,location.hash,document.referrer等)压缩成单字节,并将其标记成污点字符串.污点标记的传播规则是基于字符串实现的.**该方法改变了JavaScript 引擎 V8的底层字符串类型实现,扩展其字符串创建和分配内存方法.**同时,改变支持 DOM 的 WebKit库中字符串类的实现,增加一个数组存储成员变量的污点标记.
0X04 总结
污点分析作为信息流分析的一种实践技术,被广泛应用于互联网及移动终端平台上应用程序的信息安全保障中.本文介绍了污点分析的基本原理和通用技术,并针对近年来污点分析在解决实际应用程序安全问题时遇到的问题和关键解决技术进行了分析综述.不同于基于安全类型系统的信息流分析技术,污点分析可以不改变程序现有的编程模型或语言特性,并提供精确信息流传播跟踪.在实际应用过程中,污点分析还需要借助传统的程序分析技术的支持,例如静态分析中的数据流分析、动态分析中的代码重写等技术.另外,结合测试用例生成技术、符号执行技术以及虚拟机技术,也会给污点分析带来更多行之有效的解决方案.
0X05 参考链接
https://github.com/firmianay/CTF-All-In-One/blob/master/doc/5.5_taint_analysis.md
http://netinfo-security.org/article/2016/1671-1122-0-3-77.html#close
http://www.jos.org.cn/ch/reader/create_pdf.aspx?file_no=5190&journal_id=jos